Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks(2019)
Information retrieval 등 많은 문장을 다루는 task에 비효율적이라는 기존 BERT의 문제점을 개선한 SBERT를 소개한 논문. 이전에 다룬 siamese & triplet network를 사용해 BERT를 fine-tuning하여 문장을 다루는 여러 task의 작업 효율을 비약적으로 상승시킴과 동시에 SOTA를 달성하였다.
BERT는 문장을 입력으로 받아들여, 각각의 token의 위치마다 output을 내놓는다. 그렇다면 우리는 BERT를 사용해 어떻게 sentence 전체의 representation을 얻을 수 있을까? 기존에는 첫 번째 토큰([CLS] 토큰)의 출력으로 나오는 벡터를 사용하거나, 전체 출력의 평균을 구하는 등의 방법을 사용했다. 하지만 각각의 token에 해당하는 representation을 활용한 방법이 제대로 된 문장의 representation을 학습한 것이라고 보기는 어려웠고, 실제로 이렇게 얻은 문장의 representation은 문장의 의미를 활용하는 여러 task에서 좋지 못한 성능을 보였다. 만약 두 문장 사이의 관계를 보거나 긴 문단을 표현하려고 한다면? 문제는 더욱 복잡해지고 BERT를 활용한 예측의 정확성과 효율성은 그만큼 떨어지게 된다. 이것이 BERT를 사용해 sentence의 embedding 자체를 학습한 SBERT가 등장하게 된 배경이다.
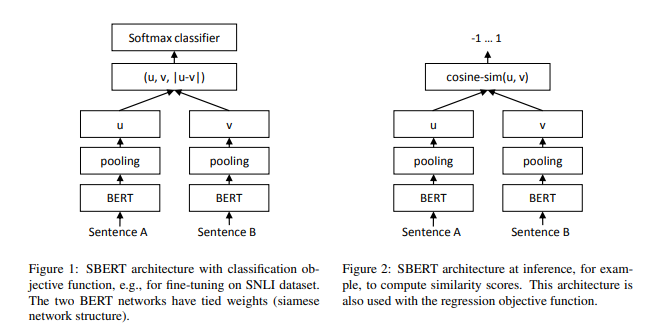
SBERT는 pretrained BERT의 output을 pooling한 뒤 cosine similarity를 사용한 triplet loss를 사용해 fine-tuning해서 얻어진 모델이기 때문에, 구조 자체는 단순하다. 그럼에도 불구하고 이 모델이 중요한 이유는, 이런 단순한 구조를 사용함에도 많은 task에서 동시에 SOTA를 달성하는 수준의 높은 성능을 보였기 때문이다. 현재까지도 question answering이나 information retrieval 등 sentence 처리와 관련된 많은 분야의 모델들이 SBERT에 뿌리를 두고 있다. 범용성이 높으면서도 강력한 두 도구인 BERT와 siamese network가 만나 만들어낸 합작품이다!
논문 링크 및 이미지 출처: https://arxiv.org/abs/1908.10084
