Attention Is All You Need(2017)
현재 분야를 막론하고 가장 활발하게 사용되는 아키텍쳐인 Transformer를 처음으로 제시한 유명한 논문. 사실 예전에 이미 두 번 정도 읽은 적이 있는 논문이지만, 다시 복습하기 위해 읽었다. 처음 개념을 이해할 때에는 참 어렵게 보였는데, 이제는 제법 빠른 속도로 읽으면서 내용을 따라갈 수 있게 되었다.
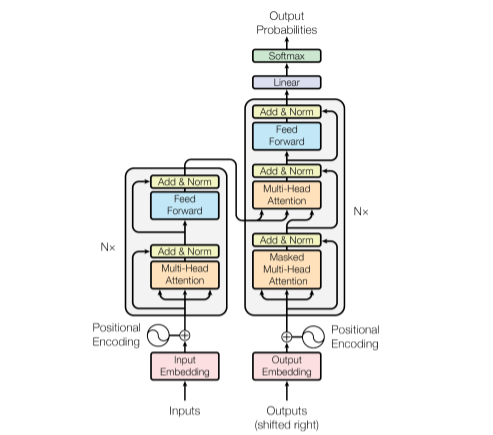
Transformer는 이전까지 NLP 분야에서 가장 많이 사용되던 RNN 기반 아키텍쳐(LSTM, GRU 등)에 고질적으로 존재하던 long-term dependency 문제를 크게 완화했다. 또한, transformer는 모델에 입력되는 토큰을 recursive하게 처리하지 않고 몇 번의 행렬 연산으로 바로 전체 attention score를 계산하기 때문에, 연산이 더 효율적이면서도 gradient가 0으로 수렴하거나 큰 값으로 발산해버리는 기존의 문제도 피해갈 수 있었다. 이러한 장점들로 인해, transformer가 발표된지 이제 5년이 되어가지만, 현재도 NLP 분야에서는 거의 모든 연구가 transformer를 기반 아키텍쳐를 사용해 이뤄지고 있다. 이제는 vision 분야에서도 vision transformer가 많은 관심을 받고 있는 것 같다(조만간 ViT 논문을 다룬 글을 쓸 생각이다).
한편, transformer 구조에 대해서는 개인적으로 약간의 의문이 남아있다. 기본적으로 transformer의 encoder는 multi-head attention layer과 feed-forward NN layer를 차례대로 거치는 과정을 여러 번 반복하는 구조로 구성되어 있다. Attention은 query와 key의 각 토큰들 사이의 관련성를 구하는 과정이기 때문에, 첫 번째의 attention layer에서 일어나는 일은 직관적으로 쉽게 이해할 수 있다. 실제로, 이 논문에 대한 해설을 보면 대부분 attention layer가 문장의 한 단어가 다른 단어들과 얼마나 관련되어 있는지 측정하는 과정이라고 시각화하여 설명한다. 하지만, 그 결과물이 value matrix와 곱해지고 다시 feed-forward NN을 거쳐서 나온 결과물이 똑같은 attention layer를 들어가고 나서부터는 무슨 일이 일어나는지에 대해서는 intuition을 얻는 것이 어렵다. 그렇기 때문에 BERT 등 transformer 기반 모델의 각 layer가 어떤 역할을 하는지 들여다보는 연구가 있었고, 이후의 layer에서는 문법적, 의미적인 측면 등 더 복잡한 층위의 정보가 담긴다고 알려졌다. 실제로 attention을 계속 반복하면 이러한 일이 일어날 만하다고 생각할 수는 있다. 하지만, 문장의 문법적, 의미적 정보를 담고자 할 때 똑같은 attention layer를 계속해서 쌓는 것이 과연 최고의 방법인가? 라고 묻는다면, 그렇다고 답하기는 어려울 것 같다. 이 부분에 대해서는 조금 더 관련 논문을 찾아보며 고민해보아야 할 것 같다.
그러나, 의심의 여지 없이 transformer 구조를 사용해 만든 현행 모델들의 성능은 많은 경우 충분할 정도로 정말 강력하다. 그렇기 때문에, transformer는 인공지능을 할 때 반드시 공부해야 하는 구조이며, 앞으로도 꽤 오랫동안은 그럴 것이다. 그런 만큼 앞으로 이와 관련해 다루어야 할 후속 논문들도 엄청나게 많다.
논문 링크 및 이미지 출처: https://arxiv.org/abs/1706.03762
