An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale(2020)
NLP 분야에서 활발하게 사용되고 있는 transformer 모델(특히 BERT)을 큰 변화 없이 그대로 vision 분야에 적용할 수 있으며, 그 image recognition 성능이 기존의 CNN 기반 SOTA 모델들과 비교할 만한 수준임을 보여주어 ViT(vision transformer)의 가능성을 입증한 논문. ViT의 구조는 transformer의 endocer 구조를 사용한 BERT와 거의 차이가 없으며, 심지어 모델의 pretraining에 사용한 여러 세팅도 기존의 BERT에 사용된 것들을 대부분 그대로 가져와 사용했다. 그렇다면, 자연스럽게 아래의 두 가지 질문을 떠올리게 될 것이다. (1) Transformer는 sequence 형태의 데이터를 입력받는 구조인데, ViT에서는 이미지를 어떻게 processing해서 transformer에 넣었을까? (2) Transformer 논문이 나온 것은 2017년이고, 당연히 그동안 vision에 transformer를 적용해보려는 시도가 많이 있었을 텐데, 왜 2020년에 이 논문이 나오기 전까지는 ResNet 기반 모델들이 여전히 우세했을까?
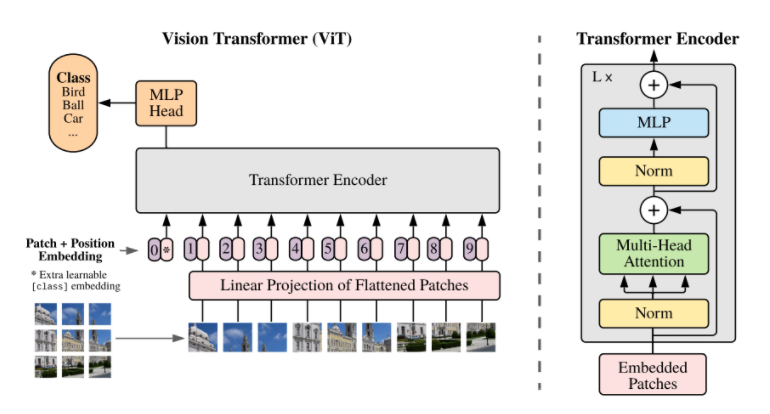
첫 번째 질문의 경우, 논문의 제목인 ‘An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale’에 그 답이 담겨 있다. ViT는 이미지를 특정 크기(ViT-L/16의 경우 16x16 사이즈)의 정사각형 patch로 나눈 뒤, flattened된 각각의 patch를 projection해 얻은 patch embedding을 positional embedding과 더해 transformer의 입력으로 사용한다. 각각의 patch를, 일종의 input token으로 생각하겠다는 것이다. 이후의 multi-head attention을 포함한 연산 과정은 BERT와 같으며, [CLS] token에 해당하는 output을 image representation으로 사용한다. 해당 image representation은 최종적으로 MLP(Multi-Layer Perceptron)를 통과해 image recognition task 수행을 위한 출력값을 만들게 된다.
이처럼 ViT는 구조가 꽤 단순하면서도 익숙하기 때문에, 위의 내용만 본다면 왜 이러한 시도가 2020년 말에 발표되었는지 의아할 수도 있다. 실제로, 해당 논문이 발표되기 전까지 transformer가 발표된 이후 지금까지 image를 2x2 size의 작은 patch로 나눠 self-attention을 적용한다거나, CNN과 attention을 함께 사용하는 등의 다양한 시도들이 있었다. 하지만, 이러한 모델들은 대부분 CNN을 기반으로 한 image recognition의 SOTA 모델에 미치지 못한 성능을 보였다. 또한, 이러한 attention 기반 모델들은 당시에 사용되던 하드웨어 가속기의 특성상 large-scale로 학습되는 것이 어려웠다. 그렇다면 ViT는 기존의 시도들과 무엇이 달랐을까? 이 논문의 저자는 이에 대해 ‘pre-training에 사용한 데이터셋의 규모’를 가장 큰 이유로 제시했다. 적은 양의 데이터셋으로 ViT를 학습시켰을 때에는 ViT 또한 기존 SOTA를 밑도는 성능을 보였지만, 데이터셋의 규모를 수천만~수억 장 수준으로 늘려서 large-scale로 학습시켜 보았더니, 새로이 SOTA를 달성하였다는 것이다. 더욱 놀라운 것은, ViT는 ResNet등의 CNN 모델보다 동일 수준의 성능을 달성하기 위해 필요한 computational cost가 훨씬 적은 것으로 나타났다. 요약하자면, ViT는 아주 많은 양의 데이터셋을 사용해 학습했을 때에 한해서는 CNN 기반 모델보다 오히려 더 높은 성능과 효율을 동시에 보일 수 있었다.
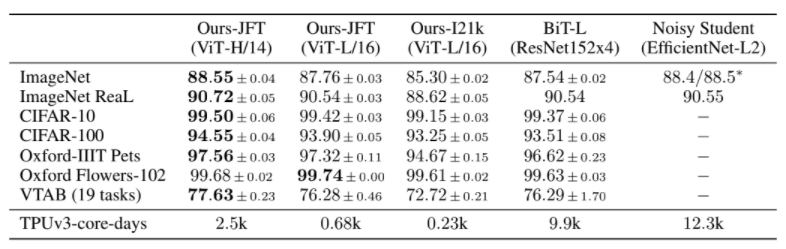
이러처럼 ViT는 여러모로 강력한 성능을 보여 많은 주목을 받았지만, 몇 가지의 해결해야 할 과제를 안고 있다. 먼저, ViT는 현재 image classification data를 활용한 supervised learning으로 학습된다. 만약 ViT를 BERT와 같이 masked patch prediction을 하도록 하는 self-supervised learning으로 학습시키면, 그 성능이 전자의 경우보다 많이 떨어진다. 그래서 저자는 이러한 contrastive pre-training으로 높은 수준의 ViT 성능을 달성하는 것을 추후의 연구 과제로 남겨놓고 있다. 다음으로, 앞서 다루었듯 ViT가 제 성능을 내기 위해서는 large-scale training을 해야 하기 때문에, 엄청난 양의 리소스가 투입되어야 한다. 위의 표의 맨 아래를 보면 ViT를 훈련시키기 위해 얼마나 많은 양의 TPU 자원이 투입되었는지 확인할 수 있다. 이와 관련된 재밌는 일화가 있는데, 해당 논문이 발표된 ICLR 학회는 double-blind review를 하기 떄문에 리뷰어들이 익명의 저자로 표시된 이 논문을 검토해야 했다. 하지만, 위의 표를 본 사람은 누구나 이 논문이 구글에서 쓴 것임을 바로 알아차릴 수 있었다고 한다. 저만한 양의 TPU 리소스를 연구에 활용할 수 있는 곳은 사실상 구글이 유일하기 때문이다..
필자는 개인적으로 이러한 결과가 서로 조금 다른 길을 걸어오던 vision과 NLP라는 두 분야가 모두 비슷한 아키텍쳐를 공유하게 되었다는 측면에서 상당히 고무적이라고 생각했다. 기존에는 각각 vision에서는 CNN, NLP에서는 RNN 기반의 아키텍쳐가 주류로 사용되었는데, 이러한 본질적인 구조의 차이가 VQA(Visual Question Answering)와 같이 두 분야의 integration을 요구하는 task를 해결하는 데에 여러모로 걸림돌이 되었다고 생각하기 때문이다. Vision과 NLP가 모두 같은 building block을 공유할 수 있게 된 만큼, 앞으로 학계에서 ViT나 BERT 등의 transformer 기반 구조를 활용해 어떤 새로운 결과물이 나오게 될지 기대된다.
논문 링크 및 이미지 출처: https://arxiv.org/abs/2010.11929
