Deep Double Descent: Where Bigger Models and More Data Hurt(2019)
모델의 bias와 variance 사이에 trade-off 관계가 존재한다는 사실은 오래 전부터 ML의 가장 기본적인 원리로 받아들여지고 있다. 모델이 너무 단순하면 underfitting이 일어나 bias가 심해 성능이 떨어지고, 반대로 모델이 너무 복잡하면 overfitting이 일어나면서 variance가 높아져 성능이 떨어지는 상황이 발생한다는 것이다. 그래서 모델 사이즈와 test error의 관계를 그리면 U-shaped curve가 만들어진다. 만약 이러한 경향성이 딥러닝에도 그대로 적용된다고 믿는다면(실제로 많은 이들이 그렇게 믿어왔다), 딥러닝 모델의 규모는 지나치게 크지 않은 것이 좋다. 그런데, 더 많은 데이터셋으로 더 큰 모델을 훈련시킬수록 좋은 성능을 보이는 최근 딥러닝 연구 동향은 이러한 컨셉을 고려했을 때 counter-intuitive하다. 2021년 구글에서 발표한 Gopher라는 SOTA 언어 모델은 기존에 볼 수 없었던 엄청난 규모인 약 2800억개의 변수를 갖는데, 이는 인간 뇌를 구성하는 뉴런 수의 추정치를 상회한다(!). 과연 이 정도 사이즈의 모델이 등장하게 된 이유는 GPT-3와 같은 기존 대규모 모델의 사이즈가 언어를 학습하기에 여전히 부족해 underfitting을 일으키기 때문일까? 그 이전에, 딥러닝 모델이 정말로 bias-variance trade-off를 따를까?
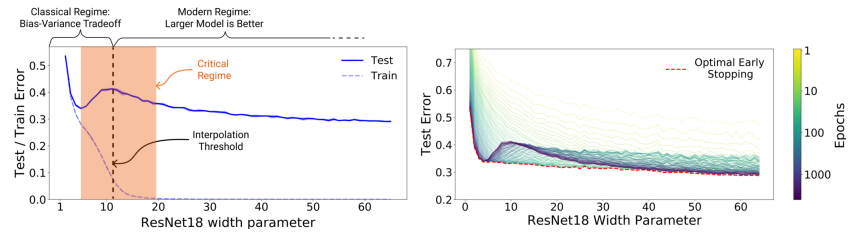
이 논문은 이러한 우리의 질문에 대해 부분적인 답과 함께, 모델의 complexity와 성능 사이의 관계를 바라보는 새로운 관점을 제시한다. 해당 논문에서는 딥러닝 모델의 complexity와 test error 사이의 관계에 대한 우리의 이해가 완전하지 않으며, bias-variance trade-off가 존재하는 영역보다 model의 complexity를 더욱 늘리면 다시 test error가 감소하는 경향을 보이게 되는 double descent 현상이 존재함을 철저한 실험을 통해 검증하였다. 위의 그림을 보면, 점선의 왼쪽 영역 우리가 잘 알고 있는 모델 사이즈와 test error 사이의 U-shaped curve를 이루고 있지만, 사이즈가 더욱 높아진 점선의 오른쪽 영역에서는 모델이 복잡해질수록 test error가 다시 점점 감소하는 경향이 나타남을 확인할 수 있다. 즉, 특정 구간부터는 모델의 복잡도가 높을수록 더 높은 성능을 보인다는 것이다. 따라서, 해당 구간부터는 early-stopping이 아무런 긍정적인 효과도 주지 않는다.
Double descent라고 불리는 이 현상이 처음 관찰된 것은 해당 논문이 발표되기 이전의 일이지만, 이 논문을 통해 해당 현상이 optimizer나 모델의 종류에 관계 없이 딥러닝 모델들에 general하게 일어나는 현상임이 처음으로 실험적으로 보여졌다. 또한, 해당 논문에서는 이러한 double descent 현상이 model size 뿐만 아니라 training epoch 수에 따른 test error를 확인했을 때에도 나타난다는 것을 발견하였다. 저자는 이러한 관찰 결과를 종합하여, 모델의 EMC(Effective Model Complexity)라는 인자를 정의한 뒤, double descent는 EMC에 의해 결정되는 함수라고 주장하였다. EMC는 “모델이 0에 가까운 training error를 달성할 수 있는 최대 training data sample의 수”로 정의되며, 모델 사이즈 뿐만 아니라 사용한 training data 샘플 수나 training epoch에 의해서도 결정되는 모델의 effective complexity의 척도다. 저자는 EMC가 실제 데이터 분포를 표현하기 위한 복잡도보다 낮으면, under-parameterized regime(위 그림의 점선 왼쪽)에, 반대로 모델의 복잡도가 데이터 분포를 표현하고 남을 정도로 충분히 복잡하면 training error가 0에 도달하고, 모델이 over-parameterized regime에(위 그림의 점선 오른쪽) 속하게 된다는 가설을 세웠다. 두 regime 사이에는 critically parameterized regime이라는 영역이 존재하는데, 해당 영역에서는 데이터셋의 변화나 모델 사이즈의 작은 변화에 따라 성능이 증가할 수도, 감소할 수도 있는데, 즉, 해당 영역에서의 모델의 동작은 아직 정확히 이해되지 않았다.
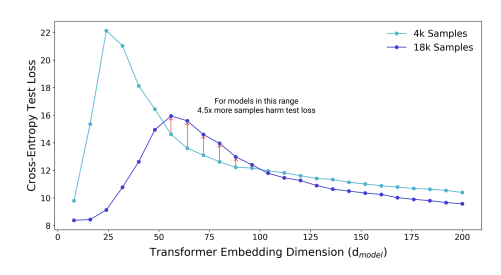
슬프게도, 여느 딥러닝 해석 문제가 그러하듯 아직 딥러닝 모델에서의 double descent를 설명할 수 있는 수학적 방법론은 없다. 그럼에도, 논문의 저자가 엄청난 양의 실험 데이터를 통해 double descent가 모델과 optimizer의 종류나 hyperparameter에 관계 없이 robust하게 나타남을 보였기 때문에, 충분한 complexity를 갖춘 모델이라면 이러한 현상이 나타날 것이라고 기대할 수 있을 것이다. 그래서 우리는 이러한 연구 결과로부터 몇 가지 교훈을 얻을 수 있다. 먼저, 충분히 큰 데이터셋이 주어진 경우, 모델은 크면 클수록, 그리고 학습은 길면 길수록 좋은 성과를 기대할 수 있다. 따라서 앞으로 딥러닝의 각 분야에서 등장하게 될 새로운 SOTA 모델들은 지금보다도 더욱 큰 규모와 요구 연산량을 갖게 될 가능성이 크다. 다음으로, 이러한 대규모 모델들을 학습시킬 경우 early-stopping을 비롯해 overfitting을 막는 것을 목적으로 고안된 regularization 방법들의 사용을 재고해볼 필요가 있다. 또한, 모델이 어중간한 capacity를 가져 critically parameterized regime에 위치한다면, 위의 그림과 같이 훈련 시 데이터셋의 규모를 키우는 것이 오히려 모델 성능을 저해시킬 수 있다(자세한 사항은 논문 참조). 마지막으로, 모델의 성능을 더욱 개선하고자 할 때 모델 사이즈에 너무 주목하기보다는, training epoch나 데이터셋 크기 등의 영향을 함께 고려하여 모델의 effective capacity(예를 들어 EMC)를 개선하는 데에 더욱 집중하는 것이 바람직할 수 있다. 이 논문에서 보여졌듯, 모델 사이즈는 training된 모델이 어떤 regime이 위치하며 어느 정도의 성능을 보여주는가에 있어 영향을 미치는 여러 요소 중 하나일 뿐이기 때문이다.
갈수록 인공지능 모델들의 크기가 커지고 training에 필요한 연산이 많아지면서 효율성이나 환경 관련 문제가 커지고 있는 가운데, 이러한 딥러닝 모델 학습 과정에 대한 이해를 통해서 가장 적은 연산으로 원하는 성능에 도달하는 방법을 찾을 수 있는 연구가 앞으로도 많이 이뤄진다면 좋겠다.
논문 링크 및 이미지 출처: https://arxiv.org/abs/1912.02292
