Perceiver: General Perception with Iterative Attention(2021)
DeepMind에서 2021년에 발표한 논문으로, 단일 구조로 다양한 modality의 데이터를 학습하고 다룰 수 있는 transformer 기반 모델인 Perceiver를 소개하였다. 기존의 AI의 각 분야에서 좋은 성과를 거둔 CNN과 transformer 기반 아키텍쳐가 다양한 modality를 학습하기 어려웠던 이유로는 크게 두 가지를 들 수 있다. 먼저, CNN의 경우 convolution이라는 연산 자체가 이미지의 형태로 들어오는 input의 spatial relationships를 가정하고 있기 때문에, 이러한 관계가 성립하지 않는 다른 형태의 데이터에는 잘 적용하기 까다로운 경우가 많다. 다음으로, BERT와 같은 transformer 구조는 input data가 정해진 길이를 가질 것을 요구하며 그 길이의 제곱에 비례해 계산 복잡도가 증가하기 때문에, 오디오 파일이나 이미지와 같이 엄청나게 긴 데이터를 downsampling이나 feature extraction 없이 그대로 받아들이는 것이 어려웠다.
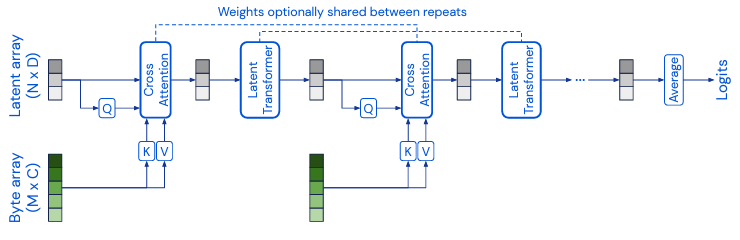
Perceiver는 위와 같이 임의의 modality의 데이터를 받아들여 cross-attention을 통해 훨씬 작은 사이즈의 latent array를 형성하고, 이것이 다시 self-attention block을 통과하는 과정이 반복되는 구조로 이루어져 있다. 이처럼 Perceiver는 앞서 설명한 CNN 기반 모델들과 달리 input으로 주어지는 정보의 modality에 대한 inductive bias를 모두 배제하는 방향으로 설계되었기 때문에, byte encoding이 가능한 구조라면 어떤 것이라도 모델이 받아들여 학습하는 것이 가능하다. 또한, 모델 중간중간에 bottleneck이 되는 레이어를 삽입하여, 아무리 길이가 길고 복잡한 데이터가 들어오더라도 각 단계마다 고정된 사이즈의 작은 벡터로 표현되게끔 하기 때문에 입력 데이터 길이에 대한 제약이 훨씬 적다.
실제로 연구진이 Perceiver를 사용해 image, audio, multimodal(video+audio) 등 다양한 modality의 데이터에 대한 classification을 학습한 것을 각각에 사용되던 다른 모델들과 비교한 결과, 동등하거나 더 뛰어난 성능을 보임을 확인하였다. 이는 Perceiver와의 비교에 사용된 각각의 모델이 해당 domain에 특화된 여러가지 inductive bias나 복잡한 연산을 사용하도록 설계되었다는 점을 고려한다면 매우 고무적인 성과이다. 이처럼 입력되는 정보를 처리하는 시스템들이 같은 building block들을 갖게 된다는 점은 multimodality를 구현하거나 모델 설계의 유연성을 늘리는 데 아주 크게 기여할 수 있기 때문에, 개인적으로 아주 흥미롭게 읽은 논문이다. 조만간 Perceiver의 출력단에도 유연성을 부여하여 다양한 길이의 structured output을 만들 수 있게 한 Perceiver IO에 대해서도 다루어볼 예정이다.
논문 링크 및 이미지 출처: https://arxiv.org/abs/2103.03206
