Data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language(2022)
이 논문은 얼마 전 메타에서 발표한 것으로, modality(vision, speech, language)에 관계 없이 적용 가능한 self-supervised learning mechanism인 Data2Vec을 제시한다. 이를 사용해 각각의 modality의 데이터를 학습시킨 결과, 각 분야에서 SOTA에 준하는 높은 성능을 보여주었다. Data2Vec이 self-supervised learning을 하는 구조는 아래와 같다.
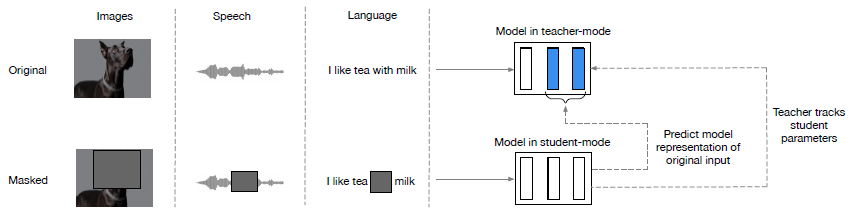
Data2Vec은 distillation과 비슷하게, student 모델이 teacher 모델과 같은 representation을 갖도록 학습하는 구조를 갖는다. 먼저, teacher와 student 모델은 같은 아키텍쳐를 공유하며, teacher 모델의 변수는 student 모델의 exponential moving average로 정해진다. Teacher 모델은 전체 데이터를 입력받고, student 모델은 masking된 데이터를 입력받는다(구체적인 masking 방법은 modality마다 조금씩 다르다. 자세한 내용은 논문 참조). 이후 각각의 모델과 input으로 representation을 계산한 뒤, masked된 시점에 해당하는 latent network representation에 대해 (해당 시점의 정보를 제공받지 못한) student model이 (전체 데이터를 제공받은) teacher model과 같은 값을 갖도록 학습시킨다. 구체적으로는, normalized된 K-top layer들의 벡터의 평균을 취한 값을 비교하여 loss를 계산한다.
이러한 방법은 기존에 존재하던 다양한 self-supervised learning mechanism과 큰 차별점을 갖는데, BERT나 self-supervised ViT처럼 출력으로 나오는 discrete한 token을 예측하지 않고, latent network representation을 예측한다는 점이다. 즉, Data2Vec은 continuous하면서도 contextualized된 representation을 학습한다. 이를 통해 Data2Vec은 discrete token이 modality에 따라 다르게 표현되어서 여러 modality의 학습에 동일한 모델을 적용하기 어렵다는 난점을 해결하였고, Data2Vec은 실제로 학습시켰을 때 여러 modality의 task에서 모두 높은 성능을 보였다.
이처럼 Data2Vec은 성능과 범용성 면에서 모두 뛰어난 면을 보여주었기 때문에, 앞으로 이를 활용해 나올 연구들이 기대된다. 특히, Data2Vec은 여전히 modality-specific한 preprocessing이나 feature extraction이 필요하며, 여러 modality를 통합적으로 학습하는 것이 아니라 각각의 modality에 대한 학습이 가능한 것 뿐이라는 한계점을 안고 있다. 전자는 이전에 다룬 Perceiver에서 일부 해결하였고, 후자의 경우는 OpenAI에서 발표한 CLIP 모델에서 text와 vision 정보를 통합적으로 학습시킬 수 있다는 가능성을 보였다. 이러한 접근 방법들을 적절히 융합한다면, 언젠가 단일 모델이 여러 modality의 정보를 받아들여 통합적으로 representation을 학습하고, 세상의 시각/청각/언어적 측면을 동시에 이해할 수 있는 인공지능이 등장하게 될지도 모르겠다. 물론 이러한 AI 모델은 여러 현실적인 걸림돌 때문에 아직까지는 상상 속의 이야기지만, 이제는 정말로 구현에 필요한 조각들이 하나하나 실현되고 있는 중이 아닌가 하는 생각이 든다. 이는 학문적, 사회적, 그리고 윤리적인 측면들을 모두 고려해서 깊게 고민해볼 만한 부분이다.
논문 링크 및 이미지 출처: https://ai.facebook.com/research/data2vec-a-general-framework-for-self-supervised-learning-in-speech-vision-and-language
