ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning(2021)
BERT의 발표 이래 최근 연구에서 다뤄지는 대부분의 NLP 모델은, 주로 self-supervised learning을 통해 pre-training된 모델을 가져다 원하는 task에 맞게 fine-tuning하여 사용한다는 공통된 흐름이 있다. Text-to-text의 형태로 모든 입출력을 다루기 때문에 단일 구조로 모든 종류의 NLP task를 수행할 수 있다는 장점을 가진 T5 또한, C4 dataset에 대한 self-supervised span denoising을 통해 pre-training을 한다. 이 논문은 이러한 T5 모델에 대해, pre-training 과정에 다양한 task에 대한 supervised learning을 포함시켜 transfer learning의 성능을 상향시킨 ExT5를 다룬다. 결론부터 이야기하면, ExT5는 pre-training 과정에서 span denoising과 함께 무려 107개의 dataset이 섞인 dataset인 ExMix에 대한(!) supervised learning을 하였고, 그 결과 얻어진 ExT5는 대부분의 NLP task에서 기존의 T5보다 높은 성능을 보였다.
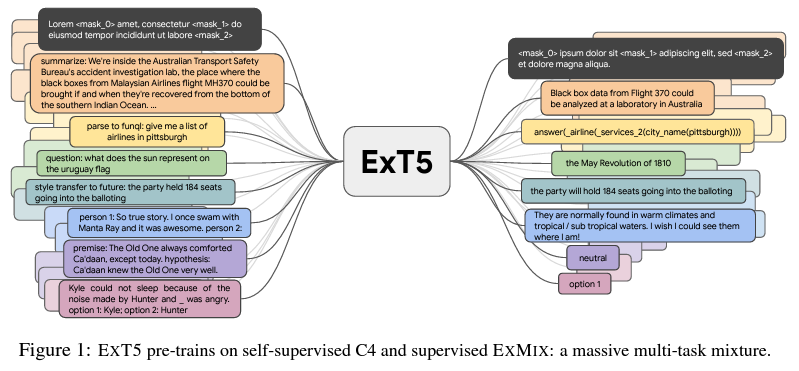
물론, 우리는 107개의 다양한 dataset 중에서, 어떤 종류의 데이터들을 골라 어떤 비율로 섞어서 pre-training에 포함시켰을 때 최적의 성능 향상을 끌어낼 수 있을지 알 수 없다. 2^107가지에 달하는 모든 가능성을 평가해볼수는 없기 때문에, 연구진은 데이터셋을 summarization, dialogue, classification, NLI 등 몇 가지의 분야로 구분한 다음, 두 분야씩 조합하여 fine-tuning을 하였을 때 특정 분야의 task 수행 성능이 얼마나 개선되는지를 확인했다. 그 결과, 아래의 표에서 볼 수 있듯 NLI처럼 대부분의 다른 task의 성능을 증가시키는 경우도 있었지만, summarization과 같이 오히려 역효과를 내는(negative transfer) 경우도 있었다.
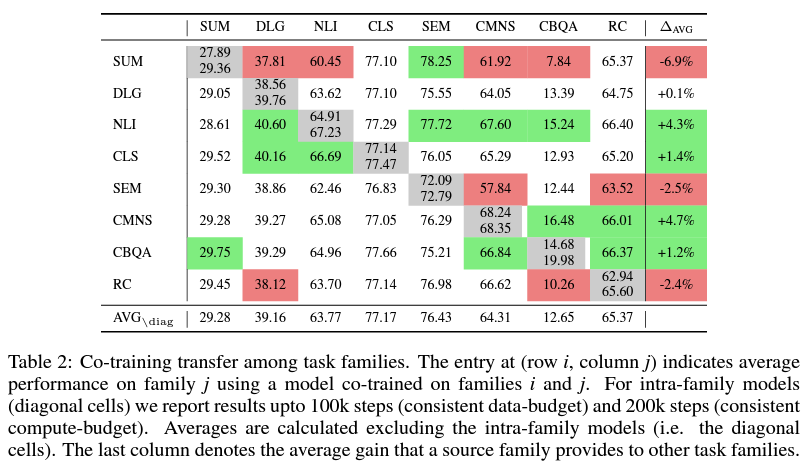
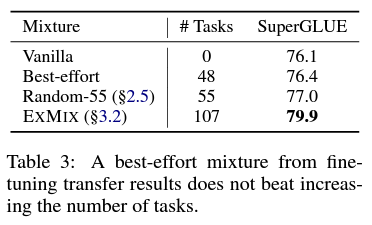
그렇다면, 위의 표에서 transfer에 긍정적인 효과를 줄 것으로 기대되는 분야의 데이터(오른쪽 끝의 값이 초록색인 데이터)만을 골라 pre-training에 사용하면 최상의 결과를 기대할 수 있지 않을까? 재미있게도, 그렇게 한 경우(아래 표의 best-effort)는 기존의 T5와 비슷한 성능을 보인 반면, 107가지의 모든 dataset을 pre-training에 포함시켰을 때(ExMix) 가장 높은 성능 향상이 있었다. 그리고, pre-training에 섞는 task의 수가 많아질수록 모델의 평균적인 성능이 상승하는 경향이 존재했다. 아쉽게도, 이러한 경향성에 대한 직접적인 설명은 추가적인 연구가 많이 이루어져야 가능할 것 같다.
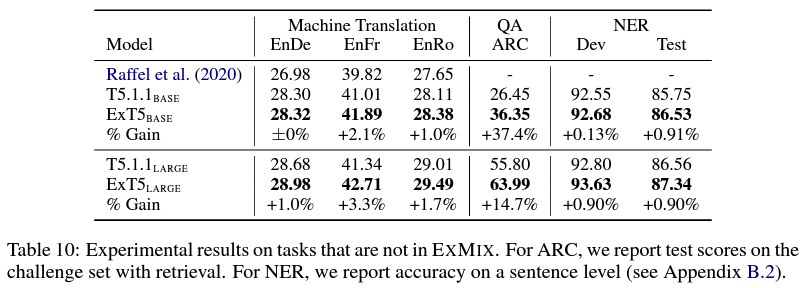
주목할 만한 부분은, ExT5가 machine translation처럼 pre-training에 사용하지 않은 종류의(out-of-mixture) task에 대해 fine-tuning했을 때에도, T5와 비교해 높은 성능 향상을 가져왔다는 점이다. 이는 대규모 multi-task pre-trainig을 거친 모델이 거의 모든 NLP task에 효과적으로 활용될 수 있음을 시사하기 때문에, 앞으로 이와 관련해 많은 추가 연구가 이뤄질 것 같다. 이러한 multi-task learning과 관련된 시도들은 task의 종류마다 loss나 모델 구조를 조금씩 다르게 설계해줄 필요가 없다는 T5의 장점과 어우러져 좋은 시너지를 만들어낼 것으로 기대된다.
논문 링크 및 이미지 출처: https://arxiv.org/abs/2111.10952
