A Metric Learning Reality Check(2020)
최근 AI의 많은 분야에서 공통적인(그리고 당연한) 연구 트렌드가 있는데, 이는 본인이 고안한 방법(아키텍쳐, optimizer, loss design 등)이 특정 데이터셋에서 SOTA를 달성함을 보여주려고 한다는 점이다. 각각의 분야와 데이터셋마다 SOTA를 갱신하기 위한 경쟁은 점점 치열해지고 있으며, 앞으로도 이런 경향은 계속되거나 더욱 심화될 것이라고 생각한다. 하지만, 이러한 경쟁 속에서도 반드시 지켜야 할 것이 있는데, 그것은 바로 데이터의 신뢰성이다. 그런데, 필자는 지금까지 여러 편의 AI 논문을 읽으며, 이 부분에 대해서 의문을 가졌던 경험이 몇 번 있었다. 예를 들어, 어떤 논문에서는 baseline과 자신의 모델을 비교평가할 때 '’해당 분야의 관행에 따라 모델의 top-1 accuracy를 비교한다’‘며 결과를 정리한 표에 confidence interval 표기 없이 top-1 accuracy만을 표기했었다. 이는 심각한 통계적 신뢰성 문제를 안고 있으며, 생명과학 논문을 많이 읽어왔던 필자는 이것이 자연과학 논문이었다면 있을 수 없는 데이터 리포팅이었기 때문에 의아했었다. 이 논문은 이러한 AI 학계의 데이터 신뢰성 문제에 대한 필자의 문제의식을 더욱 확신하게 해준 논문으로, 앞으로의 연구 및 논문 리딩에 대해 많은 생각을 하게 해주었다.
Siamese network나 triplet loss 등으로 잘 알려진 metric learning 분야는, 이후에도 다양한 loss 변형을 통해 꾸준한 연구가 이루어져 왔다. 이 논문은 제목에서 보여지듯, 이처럼 십여 년에 걸친 기존의 metric learning 분야의 성과가 과연 실제로 신뢰할 만한 것인지에 대한 철저한 분석을 담고 있다. 그리고 결론부터 이야기하면, 이 논문은 지금까지의 관련 연구들이 대부분 적절치 못한 실험 조건을 사용해 모델 성능을 과대평가했다는 심각한 공정성 문제를 안고 있으며, 실제로는 그 동안 metric learning 분야의 성능 발전이 거의 없었다고 주장한다. 이제, 논문의 저자가 이런 충격적인 결론에 도달하게 된 과정을 살펴보도록 하자.
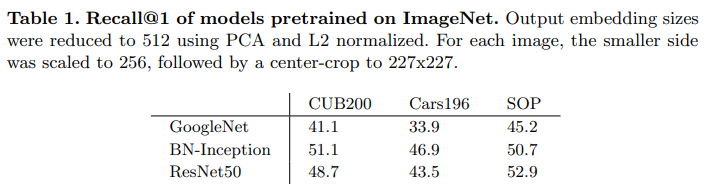
먼저, 저자는 baseline(주로 triplet loss)을 포함한 다른 기존 모델들과 새 모델을 비교할 때, 새로 변화된 부분 외적인 변인들을 조절하여 새 모델의 성능이 과대평가되도록 포장하는 일이 자주 일어남을 지적하였다. 예를 들어, 몇몇 논문에서는 자신이 design한 loss를 사용하면 기존보다 높은 성능지표를 보여줌을 주장할 때, 자신의 모델에 비교대상과는 다른 아키텍쳐를 사용해 학습을 진행시킨 결과를 리포팅하였다. 아래의 표를 보면, 해당 논문에서는 자신의 모델에는 이미 비교적 높은 pre-training 성능을 보여주는 ResNet50을 사용했지만, 비교에 사용한 나머지 모델은 GoogleNet을 사용한 결과를 제시하였다. 이렇게 된다면, 우리는 논문에서 제시한 성능 증가가 정말로 loss design의 개선에서 나온 것인지, 아니면 단지 높은 성능의 pre-trained model을 사용했기 때문인지 알 수 없게 된다. 놀랍게도, 이러한 변인통제 문제는 사용한 아키텍쳐에만 국한되지 않으며, 비교에 사용한 각 모델들의 optimizer, data augmentation 방법 등이 통일되지 않은 경우가 빈번하다고 한다. 또한, 저자는 이렇게 측정 및 기록된 지표들이 대부분 confidence interval을 포함하고 있지 않다는 점을 지적한다.
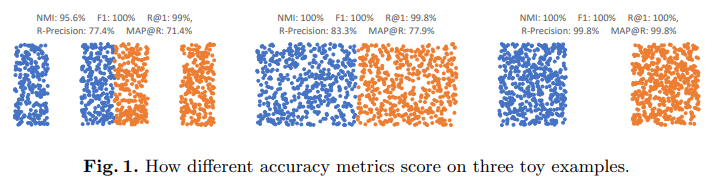
다음으로, 저자는 accuracy를 측정할 때 주로 사용되어 온 Recall@1, NMI, F1 등의 metric이 모델의 성능을 충분히 반영하는 지표인지에 대해 의문을 제기했다. 아래와 같이 데이터 분포를 생성했을 때, 각각 데이터가 분리된 정도가 명백히 다름에도 불구하고, 앞서 말한 세 종류의 metric이 이들에 대해 모두 높은 점수를 부여함을 확인할 수 있다. 또한, 이러한 측정 방식은 모델을 평가할 때 사용하는 clustering algorithm이나 (NMI의 경우) 데이터셋 사이즈에 의해 영향을 받게 되기 때문에, 모델의 성능을 제대로 반영하지 못하게 된다. 그래서, 저자는 이러한 문제를 보완하기 위해 R-precision이라는 metric을 제시하고, 이와 mean average precision을 결합해 retrieval의 순위까지 고려해 평가할 수 있는 MAP@R metric을 사용할 것을 제안하였다(자세한 정의는 논문 참조).
마지막으로, 저자는 많은 논문들이 모델 학습 과정에서 성능을 평가할 때 validation set을 사용하지 않고, 중간 단계마다 바로 test set에 대해 평가한 결과로부터 직접 피드백을 받아 hyperparamerer를 튜닝하였음을 지적했다. 원래 test set은 모델의 모든 훈련이 종료된 후 최종적으로 성능을 평가할 때에만 사용되어야 하는데, 많은 논문들이 높은 test 성능을 기록하기 위해 test set에 맞추어 훈련을 진행시킨 일종의 cheating을 했다는 것이다. 당연하게도, 이는 머신러닝 실험의 공정성을 깨뜨리는 행위이다.
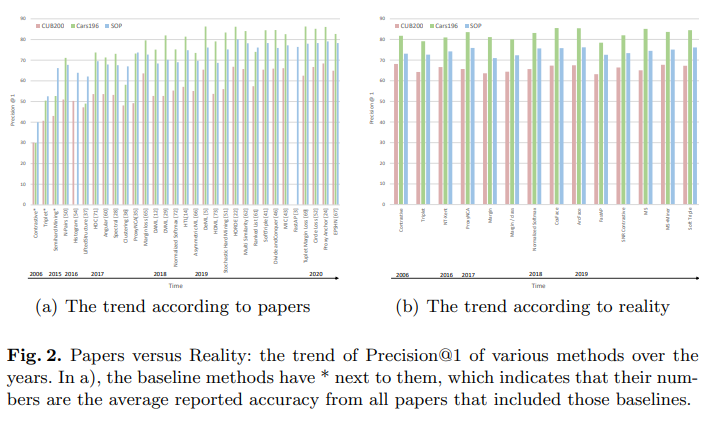
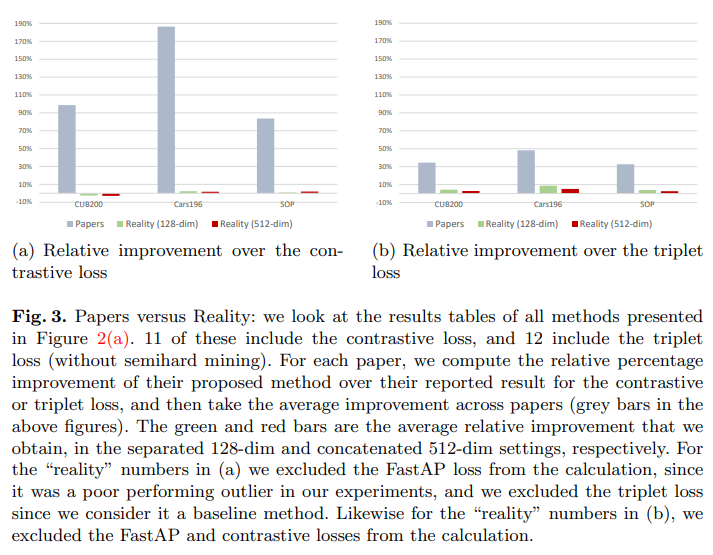
그렇다면, 이러한 문제점들을 전부 걷어내고 난 상태에서 2006부터 2019년까지 발표된 metric learning 분야의 주요 방법론의 성능을 평가하면 어떨까? 이를 위해, 저자는 아키텍쳐, data augmentation 방법, optimizer, 데이터셋, 각종hyperaprameter(learning rate, batch size 등) 등을 모두 통일한 채로 당시 발표된 metric learning의 여러 loss들만 변화시켜가며 학습하여 그 성능을 측정하였다. 그 결과는 충격적이었는데, 아래의 두 figure가 그 내용을 잘 요약하여 보여주고 있다. 첫 번째 그래프의 왼쪽은 각각의 loss를 발표한 논문에서 주장한 성능을 정리한 것인데, 시간에 따라 꾸준한 개선이 이뤄져, 가장 최근의 모델은 baseline 대비 두 배에 가까운 성능을 보이는 것으로 나타난다. 하지만 저자가 각각의 method에 대해 앞서 말한 방법으로 공정하게 평가한 결과를 나타낸 오른쪽 그래프를 보면, 실제로는 2006년의 classical method나 현재의 SOTA나 데이터셋에 무관하게 성능 차이가 거의 없었음을 확인할 수 있다. 아래의 그래프는 이 상황을 더욱 명백하게 보여주는데, 각각의 논문에서 주장한 relative improvement 대비 실제 improvement의 평균값이 현저하게 낮게 나타난다. 한 마디로, metric learning 분야에서 새로운 loss를 제시한 대부분의 논문이 부적절한 방법들을 사용해 모델의 성능이 개선된 것 같다는 환상을 만들었다는 것이 된다. 그렇다면, 우리는 자연스럽게 해당 논문들에서 성능 개선의 원인으로 제시한 해석의 정당성 또한 전부 의심해볼 필요가 있다.
왜 이러한 충격적인 경향이 몇 편의 논문에서도 아니고, 한 분야 내에서 10년 이상의 기간에 걸쳐 나타났을까? 그 원인은 결코 단순하지 않을 것이다. 필자는 아직 AI 분야에서의 연구 경험이 아주 적은 편이기 때문에 이에 대한 주관적인 의견은 적지 않겠지만, 이것이 빠르게 개선되어야 할 문제라는 것임은 분명하다. 현재로서는 논문에 주어진 정보를 최대한 비판적으로 살피는 것이 최선의 해결책이기 때문에, 앞으로 이런 부분을 잘 생각하며 주의해서 논문을 읽으려고 한다.
논문 링크 및 이미지 출처: https://arxiv.org/abs/2003.08505
