Perceiver IO: A General Architecture for Structured Inputs & Outputs(2021)
지난번에 다룬 Perceiver의 후속 논문으로. Perceiver의 경우 임의의 modality와 길이를 갖는 데이터를 최소한의 inductive bias를 사용해 처리할 수 있었으나, classification과 같이 output space가 단순한 형태를 갖는 task에만 활용될 수 있다는 한계점이 있었다. Perceiver IO는 기존 Perceiver의 구조를 약간 수정하여, output 또한 임의의 modality와 길이를 가질 수 있도록 설계하였다. 이에 따라 Perceiver IO는 natural language, visual understanding, StarCraft II 등의 다양한 task를 수행할 수 있게 되었을 뿐만 아니라 이들 모두에서 높은 성능을 보였고, 특히 Sintel optical flow estimation에서 SOTA를 달성하였다.
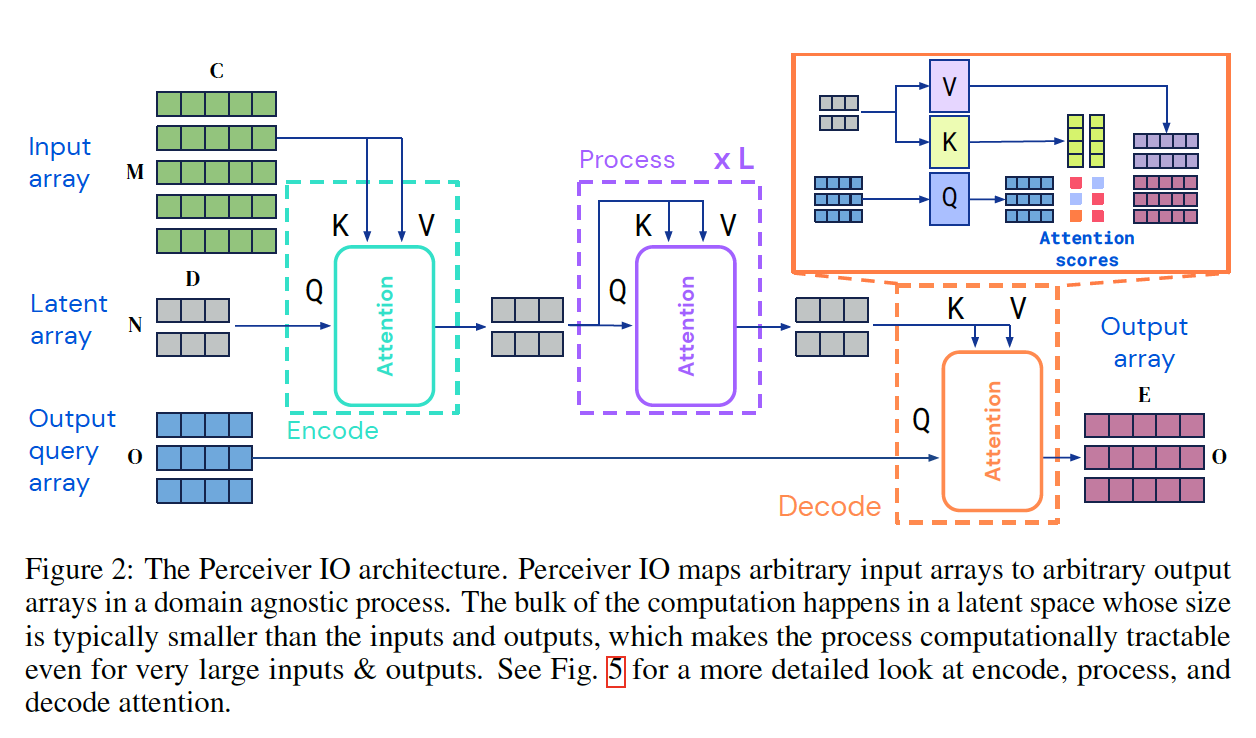
이처럼 output space를 원하는 대로 설정할 수 있게끔 한 아이디어는 단순하기 때문에, 기존 Perceiver의 구조를 잘 알고 있다면 그 아이디어를 이해하기 어렵지 않다. Perceiver에서는 임의의 길이를 갖는 input과 일정한 (그리고 일반적으로 input data보다 작은) size를 갖는 latent array에 대해 cross-attention을 수행함으로써, input의 종류에 관계 없이 항상 일정한 크기의 representation을 얻도록 하였으며, 이렇게 input을 처리하는 방식은 Perceiver IO의 경우도 동일하다. 이와 비슷하게, Perceiver IO에서는 output을 처리할 때 representation을 담고 있는 고정된 크기의 latent array를 key와 value로 사용하고, 우리가 만들어내고 싶은 output의 길이에 맞는 output query array를 query로 사용하는 cross-attention을 수행해 원하는 길이의 output을 얻게 된다. 따라서, 아래와 같이 출력하고자 하는 output의 종류(길이 및 task)에 맞추어 적절한 output query arrary를 적절히 설계해주면 된다. 이 때, output query array에는 상황에 맞게 position embedding, learned embedding, modality embedding 등을 사용한다. 또한, 맨 오른쪽의 multimodal autoencoding과 같이 다양한 modality의 output을 만들어야 하는 경우, 각각의 modality별로 다른 output query array를 설정하여 각각의 output을 얻는다.
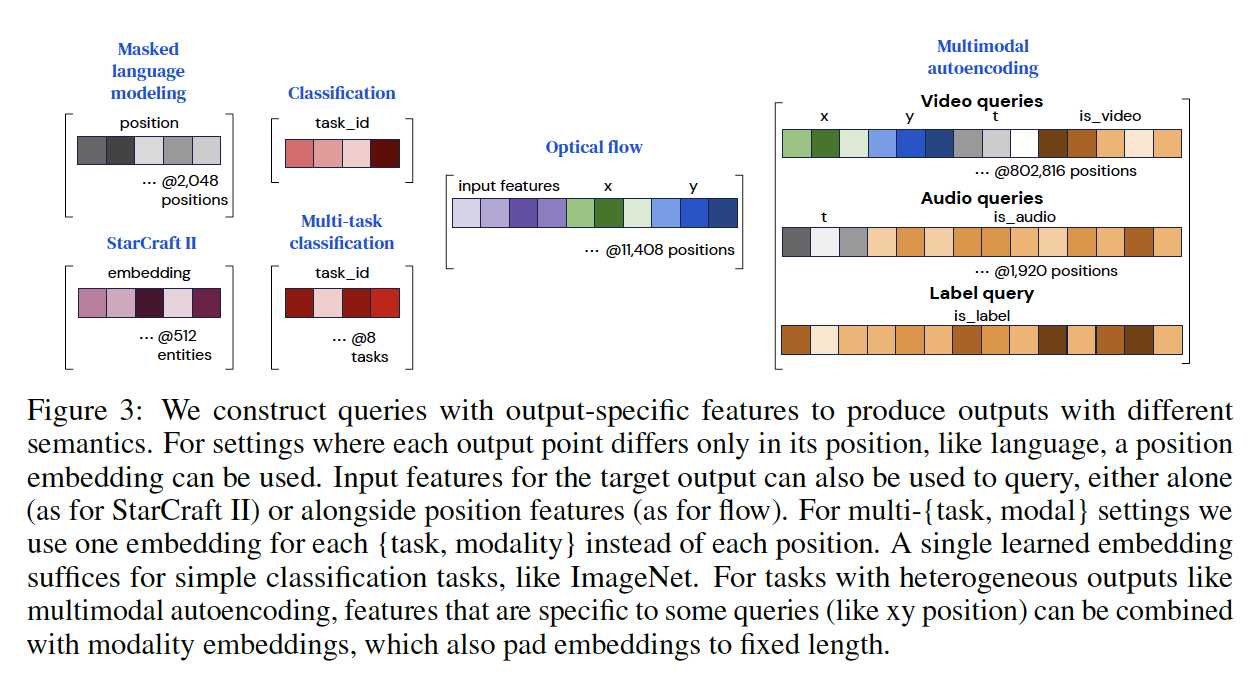
이처럼 Perceiver IO는 임의의 형태를 갖는 데이터를 입력받아 다시 임의의 형태로 출력하는 것이 가능한 구조이기 때문에, 모든 종류의 task를 수행할 수 있는 보편적인 구조라고 생각할 수도 있으나, 여전히 몇 가지 한계점을 안고 있는 것으로 보인다. 먼저, Perceiver IO는 별도의 decoder 구조를 갖지 않고 cross-attention을 통해 한 번에 output array를 생성하기 때문에, BERT와 같은 이유로 임의의 길이의 sequence를 만들어내어야 하는 generative한 task에 대해서는 적합하지 않고, 좋은 성능을 기대하기 어려울 것이다(해당 논문에서는 generative task를 포함하고 있지 않는 GLUE benchmark를 사용해 language 관련 성능을 측정하고 있다). 또한, multimodal output을 만들어내어야 하는 task의 경우, 하나의 제한된 size의 representation을 갖고 단 한 번의 cross-attention으로 각각의 modality에 대한 output을 만들어내도록 설계되어 있는데, 이 점이 task의 수행 성능을 제한할 수도 있다. 실제로, multimodal autoencoding의 경우 Perceiver IO의 성능은 그렇게 높지는 않은 것으로 보인다. 그렇다면 충분히 높은 expressivity를 갖도록 큰 size의 latent array를 사옹하거나, 각각의 modality별로 별도의 attention layer를 몇 겹 더 쌓아주면 되는 것 아니냐고 생각할 수도 있지만, 이렇게 되면 학습과 inference를 위해 필요한 연산량이 지나치게 많아지게 되어 ‘임의의 큰 size의 데이터라도 단일 구조로 효과적으로 처리할 수 있다’는 해당 모델의 정체성을 포기하게 되는 것이기 때문에, 그렇게 하지 않은 것이 아닐까 하고 개인적으로 생각한다. 향후 이러한 부분들을 개선하는 작업은 좋은 연구 주제가 될 것으로 보인다.
논문 링크 및 이미지 출처: https://arxiv.org/abs/2107.14795
